本文共 14384 字,大约阅读时间需要 47 分钟。
什么是Redis哨兵?
Sentinel(哨兵)是Redis的高可用性解决方案:由一个或者多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器,以及这些主服务器下的所有从服务器。
Sentinel使用流言协议(gossip protocols)来接收关于主服务器是否下线的信息, 并使用投票协议(agreement protocols)来决定是否执行自动故障迁移, 以及选择哪个从服务器作为新的主服务器。
哨兵的任务
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。 配置提供程序:Sentinel充当客户端服务发现的权威来源:客户端连接到Sentinels,以询问负责给定服务的当前Redis主服务器的地址。如果发生故障转移,Sentinels将报告新地址。部署前有关Sentinel的基本知识
1、一个健壮的部署至少需要三个Sentinel实例。
2、应将三个Sentinel实例放置到不同的服务器中。 3、由于Redis使用异步复制,因此Sentinel + Redis分布式系统不能保证在故障期间保留已确认的写入。但是,有一些部署Sentinel的方法使窗口丢失写入仅限于某些时刻,而还有其他一些不太安全的方法来部署它。 4、客户端需要Sentinel支持。(常见的客户端都支持Sentinel)。 5、Docker或其他形式的网络地址转换或端口映射应格外小心:Docker执行端口重新映射,会破坏Sentinel对其他Sentinel进程的自动发现以及主副本的列表。配置并启动哨兵
环境准备
准备三台已经搭建好的redis主从服务,分别为:
192.168.70.113 6379(主)
192.168.70.114 6380(从) 192.168.70.115 6381(从)三台哨兵服务分别在三个服务节点配置:
192.168.70.113 26379
192.168.70.114 26380 192.168.70.115 26381redis源码中包含了一个名为sentinel.conf的文件。

打开sentinel.conf文件,修改端口和主服务信息即可使用。
端口:
 主服务信息
主服务信息 
192.168.70.113节点配置
port 26379
sentinel monitor mymaster 192.168.70.113 6379 2192.168.70.114节点配置
port 26380
sentinel monitor mymaster 192.168.70.113 6379 2192.168.70.115节点配置
port 26381
sentinel monitor mymaster 192.168.70.113 6379 2保存退出,其他相关的配置可暂时不修改。
启动哨兵服务
- 启动哨兵之前,先启动redis主从服务。 ./redis-server /opt/redis-5.0.9/redis.conf
6379
6380
6381
- 启动哨兵 ./redis-sentinel /opt/redis-5.0.9/sentinel.conf
26379
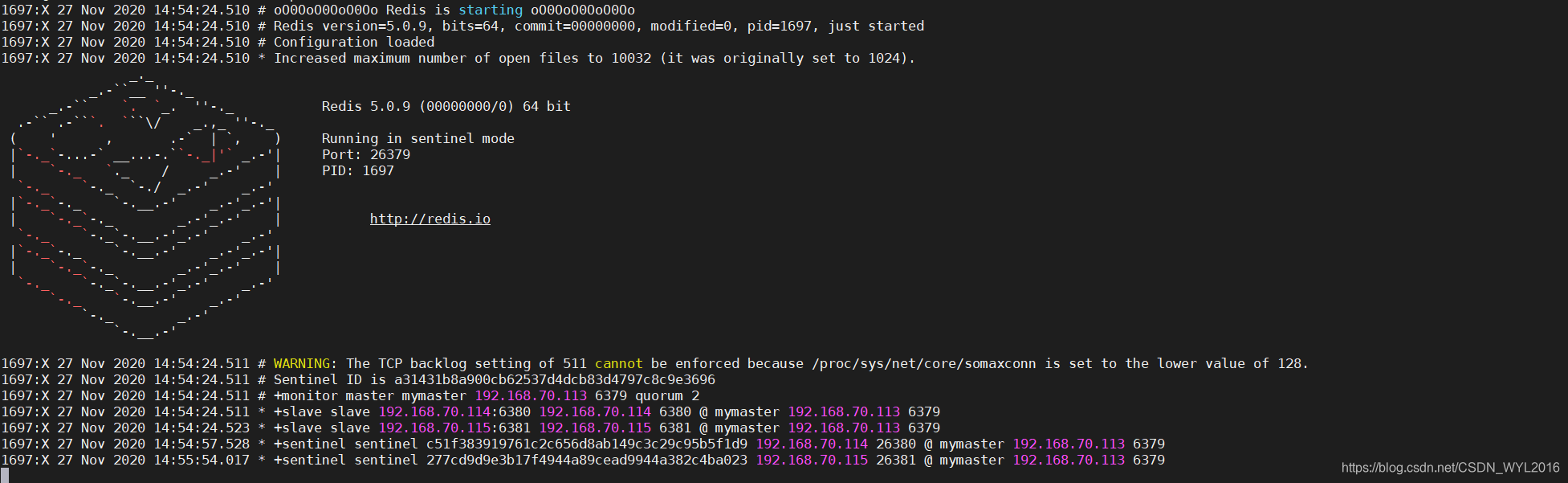
26381
哨兵故障转移演示
让6379下线

主从服务节点日志
6380被选举为主节点
3977:S 26 Nov 2020 22:20:33.301 # Error condition on socket for SYNC: Connection refused3977:S 26 Nov 2020 22:20:34.308 * Connecting to MASTER 192.168.70.113:63793977:S 26 Nov 2020 22:20:34.308 * MASTER <-> REPLICA sync started3977:S 26 Nov 2020 22:20:34.308 # Error condition on socket for SYNC: Connection refused3977:M 26 Nov 2020 22:20:34.577 # Setting secondary replication ID to 1ae15f298e299819256978b93202af51ba39e5b2, valid up to offset: 521355. New replication ID is 28bf9cd7ea64dc6120ebb416a9329d4532320f943977:M 26 Nov 2020 22:20:34.577 * Discarding previously cached master state.3977:M 26 Nov 2020 22:20:34.577 * MASTER MODE enabled (user request from 'id=8 addr=192.168.70.115:41827 fd=13 name=sentinel-277cd9d9-cmd age=2443 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=140 qbuf-free=32628 obl=36 oll=0 omem=0 events=r cmd=exec')3977:M 26 Nov 2020 22:20:34.577 # CONFIG REWRITE executed with success.3977:M 26 Nov 2020 22:20:35.645 * Replica 192.168.70.115:6381 asks for synchronization3977:M 26 Nov 2020 22:20:35.645 * Partial resynchronization request from 192.168.70.115:6381 accepted. Sending 595 bytes of backlog starting from offset 521355.

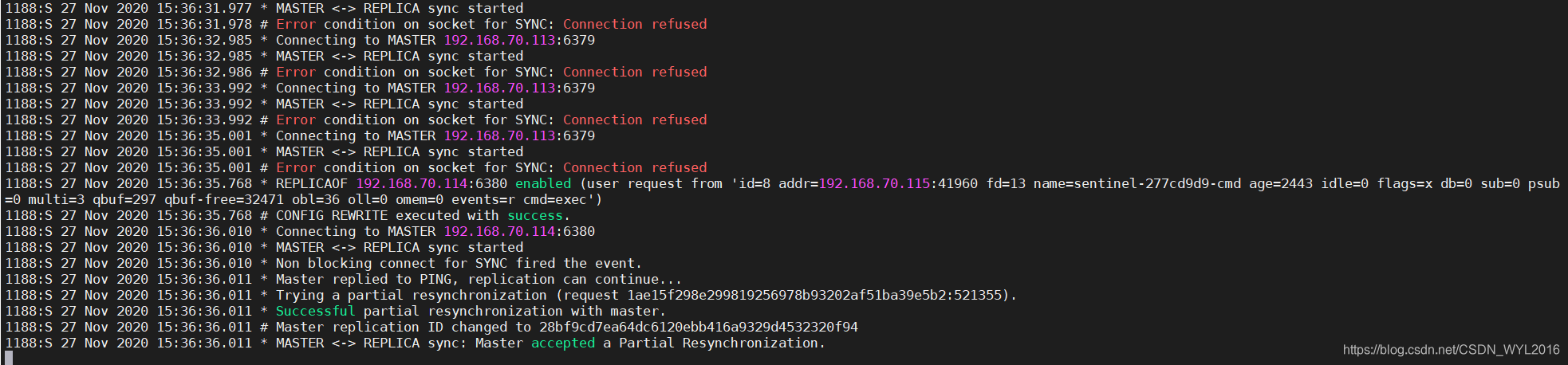
6381使用PSYNC命令与6380进行一次数据同步。
1188:S 27 Nov 2020 15:36:33.992 * MASTER <-> REPLICA sync started1188:S 27 Nov 2020 15:36:33.992 # Error condition on socket for SYNC: Connection refused1188:S 27 Nov 2020 15:36:35.001 * Connecting to MASTER 192.168.70.113:63791188:S 27 Nov 2020 15:36:35.001 * MASTER <-> REPLICA sync started1188:S 27 Nov 2020 15:36:35.001 # Error condition on socket for SYNC: Connection refused1188:S 27 Nov 2020 15:36:35.768 * REPLICAOF 192.168.70.114:6380 enabled (user request from 'id=8 addr=192.168.70.115:41960 fd=13 name=sentinel-277cd9d9-cmd age=2443 idle=0 flags=x db=0 sub=0 psub=0 multi=3 qbuf=297 qbuf-free=32471 obl=36 oll=0 omem=0 events=r cmd=exec')1188:S 27 Nov 2020 15:36:35.768 # CONFIG REWRITE executed with success.1188:S 27 Nov 2020 15:36:36.010 * Connecting to MASTER 192.168.70.114:63801188:S 27 Nov 2020 15:36:36.010 * MASTER <-> REPLICA sync started1188:S 27 Nov 2020 15:36:36.010 * Non blocking connect for SYNC fired the event.1188:S 27 Nov 2020 15:36:36.011 * Master replied to PING, replication can continue...1188:S 27 Nov 2020 15:36:36.011 * Trying a partial resynchronization (request 1ae15f298e299819256978b93202af51ba39e5b2:521355).1188:S 27 Nov 2020 15:36:36.011 * Successful partial resynchronization with master.1188:S 27 Nov 2020 15:36:36.011 # Master replication ID changed to 28bf9cd7ea64dc6120ebb416a9329d4532320f941188:S 27 Nov 2020 15:36:36.011 * MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.
哨兵节点日志
26379

26380
3983:X 26 Nov 2020 22:20:34.284 # +sdown master mymaster 192.168.70.113 63793983:X 26 Nov 2020 22:20:34.374 # +new-epoch 13983:X 26 Nov 2020 22:20:34.375 # +vote-for-leader 277cd9d9e3b17f4944a89cead9944a382c4ba023 13983:X 26 Nov 2020 22:20:34.384 # +odown master mymaster 192.168.70.113 6379 #quorum 3/23983:X 26 Nov 2020 22:20:34.384 # Next failover delay: I will not start a failover before Thu Nov 26 22:26:34 20203983:X 26 Nov 2020 22:20:35.403 # +config-update-from sentinel 277cd9d9e3b17f4944a89cead9944a382c4ba023 192.168.70.115 26381 @ mymaster 192.168.70.113 63793983:X 26 Nov 2020 22:20:35.403 # +switch-master mymaster 192.168.70.113 6379 192.168.70.114 63803983:X 26 Nov 2020 22:20:35.403 * +slave slave 192.168.70.115:6381 192.168.70.115 6381 @ mymaster 192.168.70.114 63803983:X 26 Nov 2020 22:20:35.403 * +slave slave 192.168.70.113:6379 192.168.70.113 6379 @ mymaster 192.168.70.114 63803983:X 26 Nov 2020 22:21:05.418 # +sdown slave 192.168.70.113:6379 192.168.70.113 6379 @ mymaster 192.168.70.114 6380

26381
1214:X 27 Nov 2020 15:36:34.650 # +sdown master mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:34.727 # +odown master mymaster 192.168.70.113 6379 #quorum 3/21214:X 27 Nov 2020 15:36:34.727 # +new-epoch 11214:X 27 Nov 2020 15:36:34.727 # +try-failover master mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:34.739 # +vote-for-leader 277cd9d9e3b17f4944a89cead9944a382c4ba023 11214:X 27 Nov 2020 15:36:34.741 # c51f383919761c2c656d8ab149c3c29c95b5f1d9 voted for 277cd9d9e3b17f4944a89cead9944a382c4ba023 11214:X 27 Nov 2020 15:36:34.741 # a31431b8a900cb62537d4dcb83d4797c8c9e3696 voted for 277cd9d9e3b17f4944a89cead9944a382c4ba023 11214:X 27 Nov 2020 15:36:34.798 # +elected-leader master mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:34.798 # +failover-state-select-slave master mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:34.875 # +selected-slave slave 192.168.70.114:6380 192.168.70.114 6380 @ mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:34.875 * +failover-state-send-slaveof-noone slave 192.168.70.114:6380 192.168.70.114 6380 @ mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:34.942 * +failover-state-wait-promotion slave 192.168.70.114:6380 192.168.70.114 6380 @ mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:35.695 # +promoted-slave slave 192.168.70.114:6380 192.168.70.114 6380 @ mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:35.695 # +failover-state-reconf-slaves master mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:35.767 * +slave-reconf-sent slave 192.168.70.115:6381 192.168.70.115 6381 @ mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:35.867 # -odown master mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:36.717 * +slave-reconf-inprog slave 192.168.70.115:6381 192.168.70.115 6381 @ mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:36.717 * +slave-reconf-done slave 192.168.70.115:6381 192.168.70.115 6381 @ mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:36.776 # +failover-end master mymaster 192.168.70.113 63791214:X 27 Nov 2020 15:36:36.776 # +switch-master mymaster 192.168.70.113 6379 192.168.70.114 63801214:X 27 Nov 2020 15:36:36.776 * +slave slave 192.168.70.115:6381 192.168.70.115 6381 @ mymaster 192.168.70.114 63801214:X 27 Nov 2020 15:36:36.776 * +slave slave 192.168.70.113:6379 192.168.70.113 6379 @ mymaster 192.168.70.114 63801214:X 27 Nov 2020 15:37:06.817 # +sdown slave 192.168.70.113:6379 192.168.70.113 6379 @ mymaster 192.168.70.114 6380

之后当6379重启恢复之后,将作为6380的从节点存在。
日志中输出的内容,可参考如下信息帮助理解
+reset-master :主服务器已被重置。
+slave :一个新的从服务器已经被 Sentinel 识别并关联。 +failover-state-reconf-slaves :故障转移状态切换到了 reconf-slaves 状态。 +failover-detected :另一个 Sentinel 开始了一次故障转移操作,或者一个从服务器转换成了主服务器。 +slave-reconf-sent :领头(leader)的 Sentinel 向实例发送了slaveof 命令,为实例设置新的主服务器。 +slave-reconf-inprog :实例正在将自己设置为指定主服务器的从服务器,但相应的同步过程仍未完成。 +slave-reconf-done :从服务器已经成功完成对新主服务器的同步。 -dup-sentinel :对给定主服务器进行监视的一个或多个 Sentinel 已经因为重复出现而被移除 —— 当 Sentinel 实例重启的时候,就会出现这种情况。 +sentinel :一个监视给定主服务器的新 Sentinel 已经被识别并添加。 +sdown :给定的实例现在处于主观下线状态。 -sdown :给定的实例已经不再处于主观下线状态。 +odown :给定的实例现在处于客观下线状态。 -odown :给定的实例已经不再处于客观下线状态。 +new-epoch :当前的纪元(epoch)已经被更新。 +try-failover :一个新的故障迁移操作正在执行中,等待被大多数 Sentinel 选中(waiting to be elected by the majority)。 +elected-leader :赢得指定纪元的选举,可以进行故障迁移操作了。 +failover-state-select-slave :故障转移操作现在处于 select-slave 状态 —— Sentinel 正在寻找可以升级为主服务器的从服务器。 no-good-slave :Sentinel 操作未能找到适合进行升级的从服务器。Sentinel 会在一段时间之后再次尝试寻找合适的从服务器来进行升级,又或者直接放弃执行故障转移操作。 selected-slave :Sentinel 顺利找到适合进行升级的从服务器。 failover-state-send-slaveof-noone :Sentinel 正在将指定的从服务器升级为主服务器,等待升级功能完成。 failover-end-for-timeout :故障转移因为超时而中止,不过最终所有从服务器都会开始复制新的主服务器(slaves will eventually be configured to replicate with the new master anyway)。 failover-end :故障转移操作顺利完成。所有从服务器都开始复制新的主服务器了。 +switch-master :配置变更,主服务器的 IP 和地址已经改变。 这是绝大多数外部用户都关心的信息。 +tilt :进入 tilt 模式。 -tilt :退出 tilt 模式。故障转移流程
一次故障转移操作由以下步骤组成:
- 发现主服务器已经进入客观下线状态。
- 对我们的当前纪元进行自增, 并尝试在这个纪元中当选。
- 如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。 如果当选成功, 那么执行以下步骤。
- 选出一个从服务器,并将它升级为主服务器。
- 向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
- 通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。
- 向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。
- 当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
每当一个 Redis 实例被重新配置(reconfigured) —— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里。
Sentinel选取主服务器规则
- 在失效主服务器属下的从服务器当中, 那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被淘汰。
- 在失效主服务器属下的从服务器当中, 那些与失效主服务器连接断开的时长超过 down-after 选项指定的时长十倍的从服务器都会被淘汰。
- 在经历了以上两轮淘汰之后剩下来的从服务器中, 我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器; 如果复制偏移量不可用, 或者从服务器的复制偏移量相同, 那么带有最小运行 ID 的那个从服务器成为新的主服务器。
Sentinel 自动故障迁移的一致性特质
Sentinel 自动故障迁移使用 Raft 算法来选举领头(leader) Sentinel , 从而确保在一个给定的纪元(epoch)里, 只有一个领头产生。
这表示在同一个纪元中, 不会有两个 Sentinel 同时被选中为领头, 并且各个 Sentinel 在同一个纪元中只会对一个领头进行投票。
更高的配置纪元总是优于较低的纪元, 因此每个 Sentinel 都会主动使用更新的纪元来代替自己的配置。
简单来说, 我们可以将 Sentinel 配置看作是一个带有版本号的状态。 一个状态会以最后写入者胜出(last-write-wins)的方式(也即是,最新的配置总是胜出)传播至所有其他 Sentinel 。
举个例子, 当出现网络分割(network partitions)时, 一个 Sentinel 可能会包含了较旧的配置, 而当这个 Sentinel 接到其他 Sentinel 发来的版本更新的配置时, Sentinel 就会对自己的配置进行更新。
如果要在网络分割出现的情况下仍然保持一致性, 那么应该使用 min-slaves-to-write 选项, 让主服务器在连接的从实例少于给定数量时停止执行写操作, 与此同时, 应该在每个运行 Redis 主服务器或从服务器的机器上运行 Redis Sentinel 进程。
Sentinel相关配置项
sentinel monitor mymaster 192.168.70.113 6379 2
Sentinel 去监视一个名为 mymaster 的主服务器, 这个主服务器的 IP 地址为 192.168.70.113 , 端口号为 6379 , 而将这个主服务器判断为失效至少需要 2 个 Sentinel 同意 (只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行)。
不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移, 并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。
换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。
sentinel down-after-milliseconds resque 30000
指定了 Sentinel 认为服务器已经断线所需的毫秒数。
如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误, 那么 Sentinel 将这个服务器标记为主观下线(subjectively down,简称 SDOWN )。
不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。
将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。
默认30秒。
sentinel parallel-syncs mymaster 1
指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。
sentinel failover-timeout mymaster 180000
哨兵故障转移超时<主名称> <毫秒>。
指定故障转移超时,以毫秒为单位。它可以用在很多方面:
- 给定的哨兵已经对同一主服务器进行了上一次故障转移之后,重新启动故障转移所需的时间是故障转移超时的两倍。
- 根据哨点当前配置将副本复制到错误主服务器所需的时间,强制复制到正确的主服务器所需的时间,正确的故障转移超时时间(从哨点检测到错误配置的时刻起计算)。
- 取消已经在进行但没有产生任何配置更改的故障转移所需的时间(SLAVEOF none yet not acknowledged by The promoted replica)。
- 正在进行的故障转移等待所有副本被重新配置为新主服务器副本的最大时间。然而,即使在这之后,副本仍然会由哨兵重新配置,但不会按照指定的并行同步进程进行。
默认值是3分钟。
主观下线和客观下线
前面说过, Redis 的 Sentinel 中关于下线(down)有两个不同的概念:
- 主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
- 客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。) 如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内, 对向它发送 PING 命令的 Sentinel 返回一个有效回复(valid reply), 那么 Sentinel 就会将这个服务器标记为主观下线。
服务器对 PING 命令的有效回复可以是以下三种回复的其中一种:
- 返回 +PONG 。
- 返回 -LOADING 错误。
- 返回 -MASTERDOWN 错误。 如果服务器返回除以上三种回复之外的其他回复, 又或者在指定时间内没有回复 PING 命令, 那么 Sentinel 认为服务器返回的回复无效(non-valid)。
注意, 一个服务器必须在 master-down-after-milliseconds 毫秒内, 一直返回无效回复才会被 Sentinel 标记为主观下线。
举个例子, 如果 master-down-after-milliseconds 选项的值为 30000 毫秒(30 秒), 那么只要服务器能在每 29 秒之内返回至少一次有效回复, 这个服务器就仍然会被认为是处于正常状态的。
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm), 而是使用了流言协议: 如果 Sentinel 在给定的时间范围内, 从其他 Sentinel 那里接收到了足够数量的主服务器下线报告, 那么 Sentinel 就会将主服务器的状态从主观下线改变为客观下线。 如果之后其他 Sentinel 不再报告主服务器已下线, 那么客观下线状态就会被移除。
客观下线条件只适用于主服务器: 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
只要一个 Sentinel 发现某个主服务器进入了客观下线状态, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对失效的主服务器执行自动故障迁移操作。
每个 Sentinel 都需要定期执行的任务
- 每个 Sentinel 以每秒钟一次的频率向它所知的主服务器、从服务器以及其他 Sentinel 实例发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 那么这个实例会被 Sentinel 标记为主观下线。 一个有效回复可以是: +PONG 、 -LOADING 或者 -MASTERDOWN 。
- 如果一个主服务器被标记为主观下线, 那么正在监视这个主服务器的所有 Sentinel 要以每秒一次的频率确认主服务器的确进入了主观下线状态。
- 如果一个主服务器被标记为主观下线, 并且有足够数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断, 那么这个主服务器被标记为客观下线。
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送 INFO 命令。 当一个主服务器被 Sentinel 标记为客观下线时, Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 当没有足够数量的 Sentinel 同意主服务器已经下线, 主服务器的客观下线状态就会被移除。 当主服务器重新向 Sentinel 的 PING 命令返回有效回复时, 主服务器的主观下线状态就会被移除。
TILT 模式
Redis Sentinel 严重依赖计算机的时间功能: 比如说, 为了判断一个实例是否可用, Sentinel 会记录这个实例最后一次相应 PING 命令的时间, 并将这个时间和当前时间进行对比, 从而知道这个实例有多长时间没有和 Sentinel 进行任何成功通讯。
不过, 一旦计算机的时间功能出现故障, 或者计算机非常忙碌, 又或者进程因为某些原因而被阻塞时, Sentinel 可能也会跟着出现故障。
TILT 模式是一种特殊的保护模式: 当 Sentinel 发现系统有些不对劲时, Sentinel 就会进入 TILT 模式。
因为 Sentinel 的时间中断器默认每秒执行 10 次, 所以我们预期时间中断器的两次执行之间的间隔为 100 毫秒左右。 Sentinel 的做法是, 记录上一次时间中断器执行时的时间, 并将它和这一次时间中断器执行的时间进行对比:
- 如果两次调用时间之间的差距为负值, 或者非常大(超过 2 秒钟), 那么 Sentinel 进入 TILT 模式。
- 如果 Sentinel 已经进入 TILT 模式, 那么 Sentinel 延迟退出 TILT 模式的时间。
当 Sentinel 进入 TILT 模式时, 它仍然会继续监视所有目标, 但是:
- 它不再执行任何操作,比如故障转移。
- 当有实例向这个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令时, Sentinel 返回负值: 因为这个 Sentinel 所进行的下线判断已经不再准确。
如果 TILT 可以正常维持 30 秒钟, 那么 Sentinel 退出 TILT 模式。
转载地址:http://qllrb.baihongyu.com/